Media(x) = 7.42Desviación estándar(x) = 1.15Media(y) = 75.11Desviación estándar(y) = 13.15La estadística tiene un origen que se remonta a tiempos antiguos, cuando las civilizaciones antiguas recopilaban y analizaban datos para tomar decisiones informadas en diversas áreas. Sin embargo, fue en el siglo XVII cuando los trabajos de pensadores como John Graunt y William Petty sentaron las bases para los métodos estadísticos modernos. Graunt realizó estudios sobre la mortalidad y estableció principios de recopilación de datos, mientras que Petty aplicó el análisis estadístico a la economía y la demografía.
En la era moderna, con el advenimiento de la computación y la disponibilidad de grandes volúmenes de datos, la estadística ha cobrado una importancia aún mayor. Técnicas avanzadas como el análisis de series de tiempo, la regresión múltiple, el análisis de componentes principales y el aprendizaje automático han transformado la forma en que se aborda la predicción de datos. Estas herramientas permiten modelar relaciones complejas y patrones ocultos en los datos, lo que es crucial para la toma de decisiones en áreas como el marketing, la medicina, la economía y la planificación empresarial.
(Mann 2010) presenta dos significados para la palabra “estadística”. En el sentido más común, la estadística hace referencia a hechos numéricos. El segundo significado de estadística se relaciona con el campo o disciplina de estudio. Bajo esta perspectiva, la estadística se define de la siguiente manera
Definición 3.1 (Estadística) Una estadística es una función de variables aleatorias observables, la cual es en sí misma una variable aleatoria observable y no contiene ningún parámetro desconocido.
En esta sección se definirán conceptos básicos de la estadística univariada. Se comienza con los siguientes conceptos;
Definición 3.2 (Población) Una población consiste en todos los elementos (individuos, elementos u objetos) cuyas características se están estudiando. La población que se está estudiando también se denomina población objetivo.
Definición 3.3 (Parámetro) Un parámetro es una característica numérica o descriptiva de una población o probabilidad distribución.
Un concepto sumamente útil en problemas que implican variables aleatorias o distribuciones es el de la esperanza (valor esperado). En esta subsección, se presentan definiciones y resultados relacionados con la esperanza.
Definición 3.4 (Media) Sea \(X\) una variable aleatoria. La media de \(X\), denotada por \(\mu_X\) o \(\mathrm E[X]\), se define como
\[ \mathrm E[X]= \sum x_jf_X(x_j) .\]
Si \(X\) es discreta con puntos de densidad \(x_1, x_2, \ldots, x_j, \ldots\)
\[ \mathrm E[X]=\int_{-\infty}^\infty x f_X(x)dx.\]
Si \(X\) es continua con una función de densidad de probabilidad \(f_X(x)\)
\[ \mathrm E[X]=\int_0^\infty [1-F_X(x)]dx-\int_{-\infty}^0 F_X(x) dx.\]
para cualquier variable aleatoria \(X\).
Observación. \(\mathrm E[X]\) representa el centro de gravedad (o centroide) de la región unitaria determinada por la función de densidad de \(X\). De esta manera, la media de \(X\) proporciona una medida de la ubicación central de los valores de la variable aleatoria \(X\).
La media de una variable aleatoria \(X\) es una medida de ubicación central de la densidad de \(X\). La varianza de una variable aleatoria \(X\) es una medida de la dispersión o propagación de la densidad de \(X\).
Definición 3.5 (Varianza) Sea \(X\) una variable aleatoria. Se define \(\mu_X\) como \(\mathrm E[X]\). La varianza de \(X\), denotada como \(\sigma_X^2\) o \(\mathrm{Var}[X]\), se define de la siguiente manera
\[ \mathrm{Var}[X]= \sum_j (x_j-\mu_X)^2 f_X(x_j).\]
Ahora bien, si \(X\) es discreta con puntos \(x_1, x_2, \ldots, x_j, \ldots\).
\[ \mathrm{Var}[X]=\int_{-\infty}^\infty (x-\mu_X)^2f_X(x)dx.\]
Si \(X\) es continua con una función de densidad de probabilidad \(f_X(x)\)
\[ \mathrm{Var}[X]=\int_0^\infty 2x[1-F_X(x)+F_X(-x)]dx - \mu_X^2 \]
para una variable aleatoria \(X\) arbitraria.
Se vio que una media era el centro de gravedad de una densidad; de manera similar, la varianza representa el momento de inercia de la misma densidad con respecto a un eje perpendicular que pasa por el centro de gravedad.
Definición 3.6 (Desviación estándar) Si \(X\) es una variable aleatoria, la desviación estándar de \(X\), denotada por \(\sigma_X\), se define como \(+\sqrt{\mathrm{Var}[X]}\).
La desviación estándar de una variable aleatoria, al igual que la varianza, es una medida de la dispersión o propagación de los valores de la variable aleatoria. En muchas aplicaciones, es preferible a la varianza como medida, ya que tendrá las mismas unidades de medida que la propia variable aleatoria.
Se definió la esperanza de una variable aleatoria arbitraria \(X\), llamada la media de \(X\). En esta subsección, se definirá la esperanza de una función de una variable aleatoria para variables aleatorias discretas o continuas.
Definición 3.7 (Valor esperado) Sea \(X\) una variable aleatoria y \(g(\cdot)\) una función con dominio y codominio en la recta real. La esperanza o valor esperado de la función \(g(\cdot)\) de la variable aleatoria \(X\), denotada por \(\mathrm E[g(X)]\), se define de la siguiente manera:
\[ \mathrm E[g(X)]=\sum_j g(x_j)f_X(x_j). \tag{3.1}\]
Si \(X\) es discreta con puntos \(x_1, x_2, \ldots, x_j, \ldots\) (siempre que esta serie sea absolutamente convergente),
\[ \mathrm E[g(X)]=\int_{-\infty}^\infty g(x)f_X(x)dx. \tag{3.2}\]
Si \(X\) es continua con función de densidad de probabilidad \(f_X(x)\) (siempre que \(\int_{-\infty}^\infty |g(x)|f_X(x)dx < \infty\)).
Observación. Si \(g(x)=x\), entonces \(\mathrm E[g(X)]=\mathrm E[X]\) es la media de \(X\). Si \(g(x)=(x-\mu_X)^2\), entonces \(\mathrm E[g(X)]=\mathrm E[(X-\mu_X)^2]=\mathrm{Var}[X]\).
Teorema 3.1 A continuación se presentan las propiedades del valor esperado,
\(\mathrm E[c]=c\) para una constante \(c\).
\(\mathrm E[cg(X)]=c\mathrm E[g(X)]\) para una constante \(c\).
\(\mathrm E[c_1 g_1(X)+c_2 g_2(X)]=c_1\mathrm E[g_1(X)]+c_2\mathrm E[g_2(X)]\).
\(\mathrm E[g_1(X)]\leq \mathrm E[g_2(X)]\) si \(g_1(x)\leq g_2(x)\) para todo \(x\).
Teorema 3.2 Si \(X\) es una variable aleatoria, entonces
\[\mathrm{Var}[X] = \mathrm E[(X-\mathrm E[X])^2] = \mathrm E[X^2] - (\mathrm E[X])^2, \tag{3.3}\] siempre que \(\mathrm E[X^2]\) exista.
Las pruebas de los teoremas anteriores se pueden consultar en (Mood, Graybill, y Boes 1986).
Los momentos de una variable aleatoria o de una distribución son los valores esperados de las potencias de la variable aleatoria que tiene la distribución dada.
Definición 3.8 (Momento) Si \(X\) es una variable aleatoria, el \(r-\)ésimo momento de \(X\), generalmente denotado por \(\mu_r'\), se define como
\[ \mu_r'=\mathrm E[X^r] \] si el valor esperado existe.
Note que \(\mu_1' = \mathrm E[X] = \mu_X\), es la media de \(X\).
Definición 3.9 (Cuantil) El \(q-\)ésimo cuantil de una variable aleatoria \(X\) o de su distribución correspondiente se denota como \(\xi_q\) y se define como el número más pequeño \(\xi\) que cumple con la condición \(F_X(\xi) \geq q\).
Si \(X\) es una variable aleatoria continua, entonces el \(q-\)ésimo cuantil de \(X\) se calcula como el número más pequeño \(\xi\) que cumple con la condición \(F_X(\xi) = q\).
Definición 3.10 (Mediana) La mediana de una variable aleatoria \(X\), denotada como \(\mathrm{med}_X\), \(\mathrm{med}(x)\) o \(\xi_{0.5}\), es el cuantil \(0.5\).
Definición 3.11 (Muestra) Una porción de la población seleccionada para el estudio es conocida como una muestra.
Una muestra puede ser aleatoria o no aleatoria. En una muestra aleatoria, cada elemento de la población tiene la posibilidad de ser incluido en la muestra. Sin embargo, en una muestra no aleatoria este puede no ser el caso.
Definición 3.12 (Muestra aleatoria) Sean \(X_1, X_2, \ldots, X_n\) variables aleatorias con una densidad conjunta \(f_{(X_1,\ldots, X_n)}(\cdot,\ldots, \cdot)\) que se descompone de la siguiente manera:
\[f_{X_1,X_2,\ldots, X_n}(x_1,x_2,\ldots,x_n)=f(x_1)f(x_2)\cdots f(x_n),\] donde \(f(\cdot)\) es la densidad (común) de cada \(X_i\). Entonces, se define que \(X_1, X_2, \ldots, X_n\) es una muestra aleatoria de tamaño \(n\) de una población con densidad \(f(\cdot)\).
Definición 3.13 (Media Muestral) El primer momento de la muestra es la media muestral, definida como
\[ \bar{X}= \bar{X_n}=\frac{1}{n}\sum_{i=1}^n X_i, \]
donde \(X_1, X_2, \ldots, X_n\) es una muestra aleatoria de una densidad \(f(\cdot)\). \(\bar{X}\) es una función de las variables aleatorias \(X_1, \ldots, X_n\), y por lo tanto, en teoría se puede determinar la distribución de \(\bar{X}\).
Definición 3.14 (Varianza muestral) Sea \(X_1, X_2, \ldots, X_n\) una muestra aleatoria con densidad \(f(\cdot)\), entonces
\[ S_n^2=S^2=\frac{1}{n-1}\sum_{i=1}^n (X_i-\bar{X})^2\qquad \text{para } n>1 \]
se define como la varianza muestral.
Teorema 3.3 Sea \(X_1, X_2, \ldots, X_n\) una muestra aleatoria con densidad \(f(\cdot)\), la cual tiene media \(\mu\) y varianza finita \(\sigma^2\). Si \(\bar{X} = \frac{1}{n}\sum\limits_{i=1}^n X_i\), entonces
\[ \mathrm{E}[\bar X]=\mu_{\bar X}=\mu\qquad \text{ y }\qquad \mathrm{Var}[\bar X]=\sigma_{\bar X}^2 =\frac{1}{n}\sigma^2.\]
Prueba. Vea Mood, Graybill, y Boes (1986).
Teorema 3.4 (Teorema del límite central) Supongamos que \(f(\cdot)\) es una densidad con media \(\mu\) y varianza finita \(\sigma^2\). Si \(\bar{X}_n\) es el promedio de una muestra aleatoria de tamaño \(n\) extraída de \(f(\cdot)\) y definimos la variable aleatoria \(Z_n\) como
\[ Z_n = \frac{\bar{X_n}-\mathrm E[\bar X_n]}{\sqrt{\mathrm{Var}[\bar X_n]}}=\frac{\bar X_n-\mu}{\sigma/\sqrt n},\] entonces, la distribución de \(Z_n\) se acerca a la distribución normal estándar a medida que \(n\) tiende a infinito.
Prueba. Vea Wackerly et al. (2009).
Cuando dos o más variables aleatorias son observadas en miembros de una muestra aleatoria, los datos resultantes se denominan datos multivariados. El caso especial de dos variables se refiere como datos bivariados.
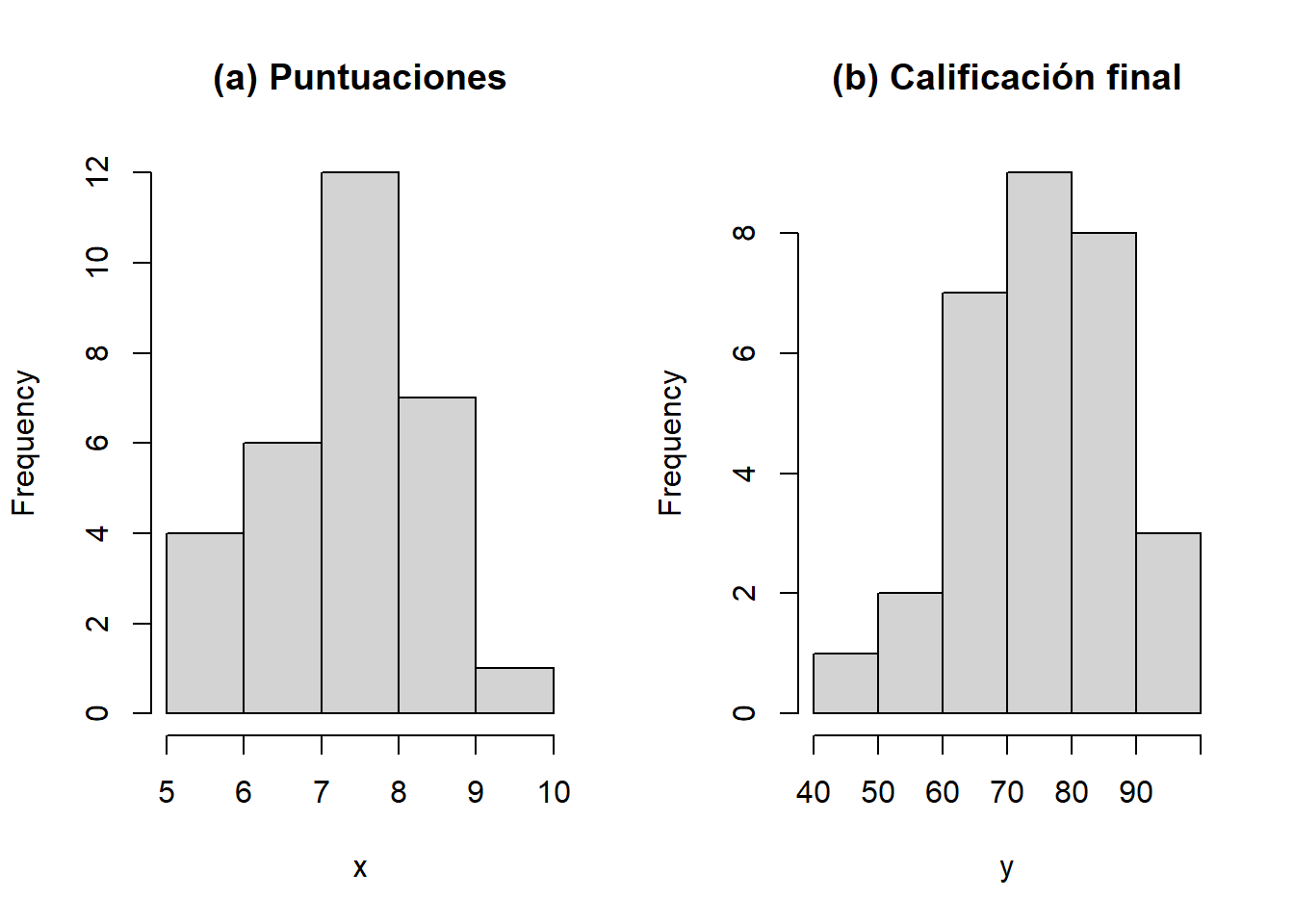
Considere los datos en la Tabla 3.1 que representan una muestra de 30 estudiantes en una universidad grande que fueron asignados al azar a un curso de Introducción a la Informática. En la Tabla se muestran las puntuaciones del cuestionario, además de la calificación del examen final de cada estudiante.
| Est. | Puntuación | Final | Est. | Puntuación | Final | Est. | Puntuación | Final |
|---|---|---|---|---|---|---|---|---|
| 1 | 7.4 | 79.8 | 11 | 7.6 | 80.7 | 21 | 8.0 | 84.2 |
| 2 | 8.4 | 82.0 | 12 | 8.8 | 94.5 | 22 | 9.0 | 87.8 |
| 3 | 8.8 | 76.1 | 13 | 6.1 | 50.1 | 23 | 8.9 | 94.1 |
| 4 | 6.4 | 62.7 | 14 | 7.2 | 68.3 | 24 | 7.5 | 78.2 |
| 5 | 10.0 | 98.2 | 15 | 6.6 | 64.4 | 25 | 5.5 | 62.4 |
| 6 | 5.5 | 43.0 | 16 | 7.0 | 67.2 | 26 | 8.5 | 85.1 |
| 7 | 7.3 | 76.5 | 17 | 5.3 | 53.9 | 27 | 7.4 | 77.8 |
| 8 | 5.9 | 61.4 | 18 | 7.9 | 78.8 | 28 | 6.3 | 67.6 |
| 9 | 7.1 | 78.5 | 19 | 8.1 | 85.7 | 29 | 7.7 | 70.2 |
| 10 | 7.9 | 88.7 | 20 | 7.6 | 81.7 | 30 | 6.9 | 73.6 |
| Suma | 222.6 | 2253.2 |
Los valores medios y las desviaciones estándar se proporcionan a continuación. Las puntuaciones del cuestionario están en el vector \(x\) y las puntuaciones del examen final están en \(y\). Se tienen los siguientes resultados:
Media(x) = 7.42Desviación estándar(x) = 1.15Media(y) = 75.11Desviación estándar(y) = 13.15Los histogramas de estas dos variables se muestran en la Figura 3.1. Allí se puede observar que los histogramas de ambas variables tienen una forma aproximadamente en campana, con las puntuaciones del examen final ligeramente sesgadas hacia la izquierda. Al examinar el histograma en la Figura 3.1(b), se observa que la media de las puntuaciones del examen final parece ser de alrededor de 75, lo cual es coherente con los resultados anteriores. La mayoría de las puntuaciones están entre 60 y 90, con algunas por encima de 90 y algunas por debajo de 60.
Los histogramas, las medias y las desviaciones estándar no proporcionan información sobre cómo dos variables están relacionadas entre sí. Como ejemplo, un instructor probablemente quisiera saber si los estudiantes que les fue bien en el cuestionario también tendieron a desempeñarse bien en el examen final, y viceversa. También podría querer saber si algunos estudiantes que les fue mal en el cuestionario mejoraron drásticamente su calificación en el examen final. Los histogramas y las estadísticas de muestra mostrados anteriormente no responden a estas preguntas.
Lo que se necesita son medidas de la relación entre las dos variables. Los parámetros poblacionales más comunes utilizados para medir tales relaciones son la covarianza, \(\gamma_{XY}\), y la correlación, \(\rho_{XY}\).
Definición 3.15 (Covarianza) Si \(X\) e \(Y\) son dos variables aleatorias definidas en el mismo espacio de probabilidad, la covarianza de \(X\) e \(Y\), denotada como \(\mathrm{Cov}[X,Y]\) o \(\gamma_{XY}\), se define como \[\gamma_{XY}=\mathrm{Cov}[X,Y]=\mathrm E[(X-\mu_X)(Y-\mu_Y)]\] siempre que la esperanza indicada exista.
Definición 3.16 (Correlación) La correlación, denotada como \(\rho[X,Y]\) o \(\rho_{XY}\), de las variables aleatorias \(X\) e \(Y\), se define como
\[ \rho_{XY}=\frac{\gamma_{XY}}{\sigma_X \sigma_Y} \]
siempre que \(\gamma_{XY}, \sigma_X\) y \(\sigma_Y\) existan, con \(\sigma_X, \sigma_Y>0\).
Técnicamente, la covarianza es el valor esperado (o promedio teórico) del producto cruzado \((X-\mu_X)(Y-\mu_Y)\). Es una medida de cómo dos variables “se mueven juntas”. Para facilitar la interpretación, generalmente se usa la correlación, que es una versión “estandarizada” de la covarianza que tiene la propiedad \(-1 \leq \rho_{XY}\leq 1\) para cualquier par de variables aleatorias \(X\) e \(Y\).
Observación.
\(\gamma_{XX}=\mathrm E[(X-\mu_X)(X-\mu_X)]=\mathrm E[(X-\mu_X)^2]=\sigma_X^2\).
\(\rho_{XX}=\frac{\sigma_X^2}{\sigma_X \sigma_X}=1\).
Corolario 3.1 Si \(X\) e \(Y\) son independientes, entonces \(\gamma_{XY}=0\).
Prueba. Observe que
\[ \begin{split}\mathrm{Cov}[X,Y]=\mathrm E[(X-\mu_X)(Y-\mu_Y)]=\mathrm E[X-\mu_X]\mathrm E[Y-\mu_Y]=0,\end{split} \]
ya que \(\mathrm E[(X-\mu_X)]=0\).
Teorema 3.5 Sean \(X\) e \(Y\) variables aleatorias definidas sobre el mismo espacio de probabilidad tales que \(E(X^2) < \infty\) y \(E(Y^2) < \infty\). Entonces:
\(\mathrm{Cov}[X, Y]= \mathrm{E}[XY]-\mathrm{E}[X]\mathrm{E}[Y]\).
\(\mathrm{Cov}[X, Y]= \mathrm{Cov}[Y,X]\).
\(\mathrm{Var}[X]= \mathrm{Cov}[X,X]\).
\(\mathrm{Cov}[aX+b, Y]= a\mathrm{Cov}[X, Y]\) para cualquier \(a,b \in\mathbb{R}\).
Prueba. Vea Castañeda, Arunachalam, y Dharmaraja (2014).
Definición 3.17 (Variables aleatorias no correlacionadas) Las variables aleatorias \(X\) e \(Y\) se definen como no correlacionadas si y solo si \(\mathrm{Cov}[X,Y]=0\).
Observación. La afirmación contraria al corolario anterior no siempre es cierta; es decir, \(\mathrm{Cov}[X,Y]=0\) no siempre implica que \(X\) e \(Y\) sean independientes.